Introduction: Facebook claims that fastText is much faster than other learning methods. It can train models to handle more than a billion words in 10 minutes using standard multi-core CPUs. In particular, compared to the depth model, fastText can improve training time. Reduce days to seconds.

Facebook FAIR Lab announced in the latest blog that the open source database fastText, claimed that compared to the depth model, fastText can reduce training time from days to seconds.
| Use fastText for faster, better text categorization
Understanding what people are talking about, or what they are saying at the time of the article is one of the biggest technical challenges for AI researchers, but it is also a key requirement. Automatic text processing is quite critical in everyday computer use and is an important part of web search and content ranking and spam content classification. And you can't feel it completely when it's running. As the total amount of online data is increasing, more flexible tools are needed to better understand these large data sets to provide more accurate classification results.
In order to meet this demand, Facebook FAIR Lab open source fastText. fastText is a database that helps establish quantitative solutions for text expression and classification . With regard to the implementation of fastText, Facebook has also published two related papers. The specific information of the two papers is as follows:
Bag of Tricks for Efficient Text Classification

Enriching Word Vectors with Subword Information (Using Subword Information Rich Vocabulary Vectors)

fastText combines the most successful ideas in natural language processing and machine learning. These include the use of word bags and n-gram bag representation statements, as well as the use of subword information, and the sharing of information between categories through hidden representations. We also use a softmax level (which takes advantage of the uneven distribution of categories) to speed up the calculation process. These different concepts are used for two different tasks:
Valid text classification
Learning Word Vector Representation
For example: fastText can learn that "boy", "girl", "man", and "woman" refer to specific genders and can store these values ​​in related documents. Then, when a program asks for a user request (assuming "my girlfriend is now?"), it can immediately look up the file generated by fastText and understand what the user wants to ask about women.
fastText's implementation of text classification
Deep neural networks have recently become very popular in the field of text processing, but their training and testing process has been slow, which also limits their application on large data sets.
fastText can solve this problem, and its implementation is as follows:
For a large set of datasets, fastText uses a hierarchical classifier (rather than a flattened one). Different categories are integrated into the tree structure (imagine a binary tree instead of a list).
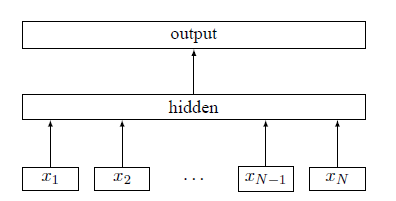
Taking into account the linear and multi-category logarithmic model, this greatly reduces the training complexity and the time to test the text classifier. fastText also takes advantage of the fact that class imbalances occur (some classes appear more often than others) and use the Huffman algorithm to build a tree structure for characterizing classes. Therefore, the depth of the frequently occurring tree structure is smaller than that of the infrequent tree structure, which also makes the further calculation more efficient.
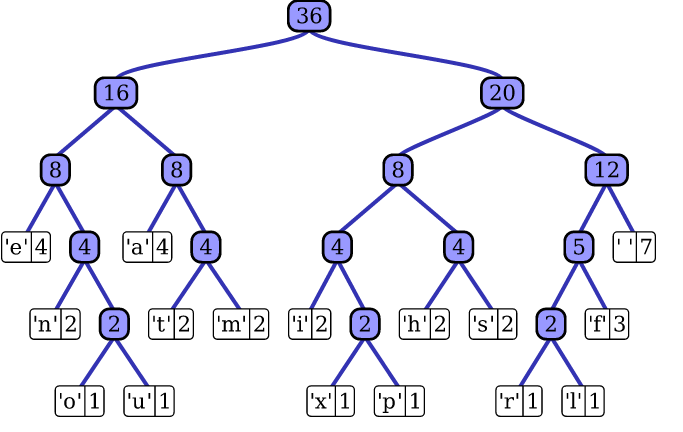
Huffman algorithm
fastText also uses a low-dimensional vector to characterize the text and obtains by summarizing the word vectors that appear in the corresponding text. A low-dimensional vector in fastText is associated with each word. Hidden characterization is shared among all classifiers in different categories so that textual information can be used together in different categories. Such characterizations are called bag of words (where the word order is ignored). The use of vector representations of word n-grams in fastText also takes into account local word order, which is important for many text categorization problems.
Experiments have shown that fastText has the same level of accuracy as deep learning classifiers, especially at training and evaluation rates that are several orders of magnitude higher. Using fastText can reduce training time from days to seconds , and achieve best performance today (such as text bias analysis or tag prediction) on many standard issues.

Comparison of FastText and Char-CNN and VDCNN Based on Deep Learning Method Â
| fastText can also be used as a professional tool
Text classification is very important for the business community. Spam or phishing email filters may be the most typical example. There are already tools that can be used to design models for general classification problems such as Vowpal Wabbit or libSVM, but fastText focuses on text classification. This allows it to be quickly trained on particularly large data sets. We used a standard multi-core CPU and got the result of training over 1 billion vocabulary models in 10 minutes. In addition, fastText can divide 500,000 sentences into more than 300,000 categories in five minutes.
| fastText is common to many languages
In addition to text classification, fastText can also be used to learn vocabulary vector representations. With its morphological structure, fastText can be designed to support multiple languages ​​including English, German, Spanish, French, and Czech. It also uses a simple and efficient way to include sub-word information. This method works very well when used in a plentiful language like Czech, which also proves a well-designed character n-gram feature. Is an important source of rich vocabulary representation. FastText's performance is significantly better than the popular word2vec tool, and it is better than other current state-of-the-art morphological vocabulary characterizations.
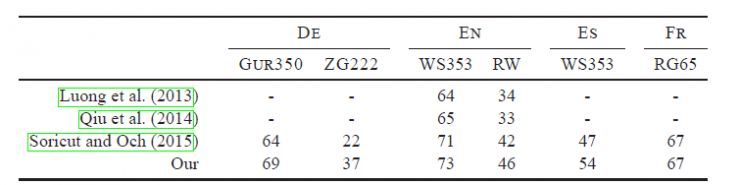
FastText compares to the most advanced vocabulary characterization in different languages
fastText specific code implementation process
fastText is based on the Mac OS or Linux system and uses the features of C++11. Requires Python 2.6 or later support, as well as software support such as numpy & scipy.
Example:
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ make
$ ./fasttext supervised
Empty input or output path.
The following arguments are mandatory:
-input training file path
-output output file path
The following arguments are optional:
-lr learning rate [0.05]
-dim size of word vectors [100]
-ws size of the context window [5]
-epoch number of epochs [5]
-minCount minimal number of word occurences [1]
-neg number of negatives sampled [5]
-wordNgrams max length of word ngram [1]
-loss loss function {ns, hs, softmax} [ns]
-bucket number of buckets [2000000]
-minn min length of char ngram [3]
-maxn max length of char ngram [6]
-thread number of threads [12]
-verbose how often to print to stdout [10000]
-t sampling threshold [0.0001]
-label labels prefix [__label__]
Summary: Facebook FAIR Lab's latest open source tool, fastText, can reduce training time from days to seconds. Compared to deep learning based model methods, fastText speeds are orders of magnitude faster, while maintaining equal accuracy. In addition, fastText can also be used as a professional tool for text classification in practical applications, especially for large datasets that can achieve very fast training speeds. In addition, fastText also supports multiple languages ​​including English, German, Spanish, French, and Czech because of its own language structure.
PS : This article was compiled by Lei Feng Network (search "Lei Feng Network" public number attention) , refused to reprint without permission!
Via Facebook research blog